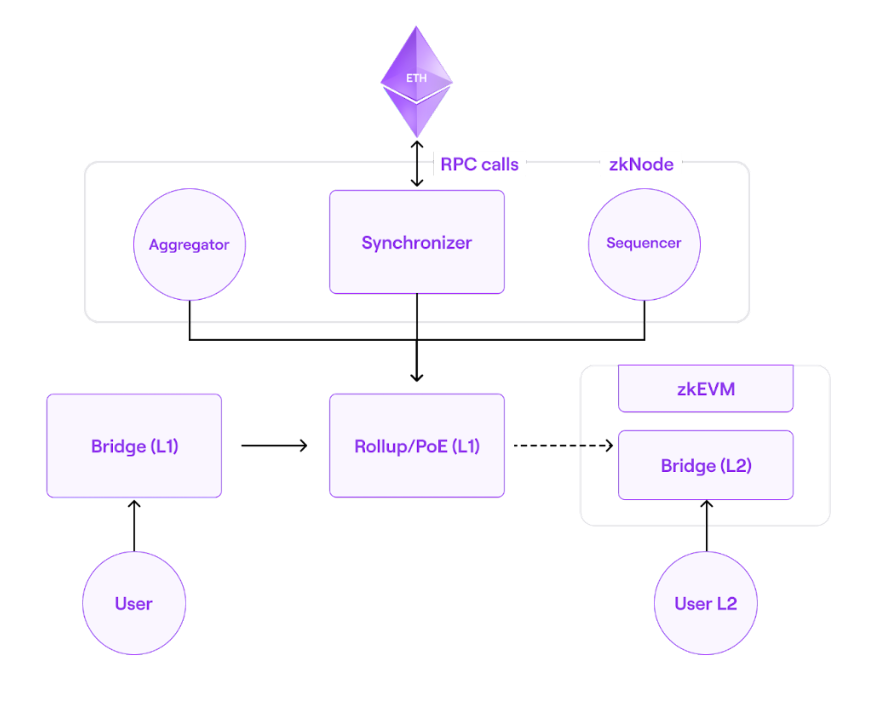
Architecture
Polygon zkEVM handles state transitions caused by Ethereum Layer 2 transaction executions (transactions that users send to the network). Following that, it creates validity proofs that attest to the accuracy of these off-chain state change calculations by utilizing zero-knowledge features.
The major components of zkEVM are:
- Consensus contract (PolygonZkEVM.sol)
- zkNode
- Synchronizer
- Sequencers & aggregators
- RPC
- zkProver
- zkEVM bridge
The skeletal architecture of Polygon zkEVM is shown below:
Consensus contract¶
The earlier version, Polygon Hermez 1.0, was based on the Proof of Donation (PoD) consensus mechanism. PoD was basically a decentralized auction conducted automatically, with participants (coordinators) bidding a certain number of tokens in order to be chosen to create the next batch.
Our latest Consensus Contract (PolygonZkEVM.sol) leverages the experience of the existing PoD in v1.0 and adds support for the permissionless participation of multiple coordinators to produce batches in L2.
The earlier Proof of Donation (PoD) mechanism was based on a decentralized auction model to get the right to produce batches in a specific timeframe. In this mechanism, the economic incentives were set up so the validators need to be very efficient in order to be competitive.
The latest version of the zkEVM Consensus Contract (deployed on Layer 1) is modelled after the Proof of Efficiency. It leverages the experience of the existing PoD in v1.0 and adds support for the permissionless participation of multiple coordinators to produce batches in L2.
Implementation model¶
The Consensus Contract model leverages the existing PoD mechanism and supports the permissionless participation of multiple coordinators to produce batches in L2. These batches are created from the rolled-up transactions of L1. The Consensus Contract (PolygonZkEVM.sol) employs a simpler technique and is favoured due to its greater efficiency in resolving the challenges involved in PoD.
The strategic implementation of the contract-based consensus promises to ensure that the network:
- Maintains its permissionless feature to produce L2 batches.
- Is highly efficient, a criterion which is key for the overall network performance.
- Attains an acceptable degree of decentralization.
- Is protected from malicious attacks, especially by validators.
- Maintains a fair balance between overall validation effort and network value.
Tip
Good to Know
Possibilities of coupling the Consensus Contract (previously called Proof of Efficiency or PoE) with a PoS (Proof of Stake) are currently being explored. A detailed description is published on the Ethereum Research website.
On-chain data availability¶
A full zkRollup schema requires the publication of both the data (which users need to reconstruct the full state) and the validity proofs (zero-knowledge proofs) on-chain. However, given the Ethereum configuration, publishing data on-chain incurs gas prices, which is an issue with Layer 1. This makes deciding between a Full ZK-Rollup configuration and a Hybrid configuration challenging.
Under a Hybrid schema, either of the following is possible:
- Validium: Data is stored off-chain and only the validity proofs are published on-chain.
- Volition: For some transactions, both the data and the validity proofs remain on-chain while for the remaining ones, only proofs go on-chain.
Unless, among other things, the proving module can be highly accelerated to mitigate costs for the validators, a Hybrid schema remains viable.
PolygonZkEVM.sol¶
The underlying protocol in zkEVM ensures that the state transitions are correct by employing a validity proof. To ensure that a set of pre-determined rules have been followed for allowing state transitions, the consensus contract (PolygonZkEVM.sol, deployed on L1) is utilized.
Info
The consensus contract is currently deployed on both Ethereum Mainnet and Goerli Testnet.
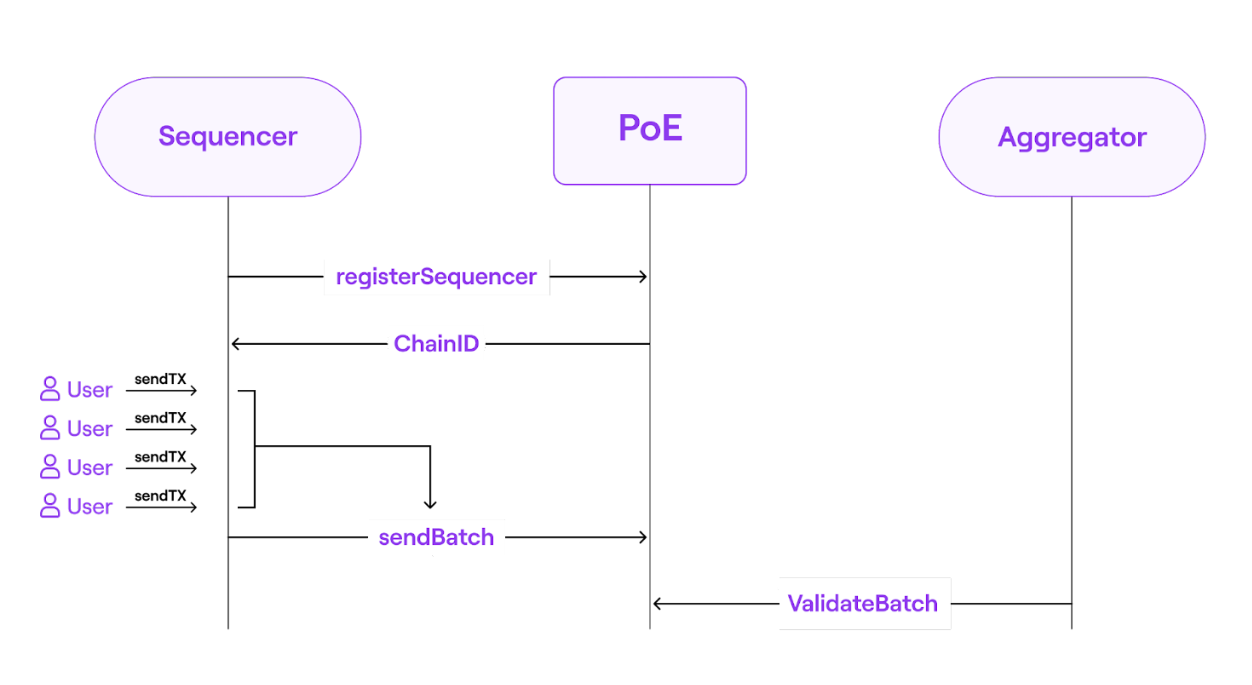
A smart contract verifies the validity proofs to ensure that each transition is completed correctly. This is accomplished by employing zk-SNARK circuits. A system of this type requires two processes: transaction batching and transaction validation.
To carry out these procedures, zkEVM employs two sorts of participants: sequencers and aggregators. Under this two-layer model:
- Sequencers → propose transaction batches to the network, i.e. they roll-up the transaction requests in batches and add them to the Consensus Contract.
- Aggregators → check the validity of the transaction batches and provide validity proofs. Any permissionless aggregator can submit the proof to demonstrate the correctness of the state transition computation.
The smart contract, therefore, makes two calls: one to receive batches from sequencers, and another to aggregators, requesting batches to be validated.
Tokenomics¶
The consensus smart contract imposes the following requirements on sequencers and aggregators:
Sequencers¶
- Anyone with the software necessary for running a zkEVM node can be a sequencer.
- Every sequencer must pay a fee in form of MATIC tokens to earn the right to create and propose batches.
- A sequencer that proposes valid batches (which consist of valid transactions), is incentivized with the fee paid by transaction-requestors or the users of the network.
Aggregators¶
An aggregator receives all the transaction information from the sequencer and sends it to the prover which provides a small zk-proof after complex polynomial computations. The smart contract validates this proof. This way, an aggregator collects the data, sends it to the prover, receives its output and finally, sends the information to the smart contract to check that the validity proof from the prover is correct. - An aggregator’s task is to provide validity proofs for the L2 transactions proposed by sequencers. - In addition to running zkEVM’s zkNode software, aggregators need to have specialized hardware for creating the zero-knowledge validity proofs utilizing zkProver. - For a given batch or batches, an aggregator that submits a validity proof first earns the MATIC fee (which is being paid by the sequencer(s) of the batch(es)). - The aggregators need to indicate their intention to validate transactions. After that, they compete to produce validity proofs based on their own strategy.
zkNode¶
zkNode is the software needed to run any zkEVM node. It is a client that the network requires to implement the synchronization and govern the roles of the participants (sequencers or aggregators). Polygon zkEVM participants will choose how they participate:
- As a node to know the state of the network, or;
- As a participant in the process of batch production in any of the two roles: sequencer or aggregator.
The zkNode architecture is modular in nature. You can dig deeper into zkNode and its components here.
Incentivization structure¶
The two permissionless participants of the zkEVM network are sequencers and aggregators. Proper incentive structures have been devised to keep the zkEVM network fast and secure. Below is a summary of the fee structure for sequencers and aggregators:
- Sequencer
- Collect transactions and publish them in a batch.
- Receive fees from the published transactions.
- Pay L1 transaction fees + MATIC (depends on pending batches).
- MATIC goes to aggregators.
- Profitable if:
txs fees>L1 call+MATICfee. - Aggregator
- Process transactions published by sequencers.
- Build zkProof.
- Receive MATIC from sequencer.
- Static cost: L1 call cost + server cost (to build a proof).
- Profitable if:
MATIC fee>L1 call+server cost
zkProver¶
zkEVM employs advanced zero-knowledge technology to create validity proofs. It uses a zero-knowledge prover (zkProver), which is intended to run on any server and is being engineered to be compatible with most consumer hardware. Every aggregator will use this zkProver to validate batches and provide validity proofs.
It consists of a main state machine executor**, a collection of secondary state machines (each with its own executor), a STARK-proof builder, and a SNARK-proof builder.
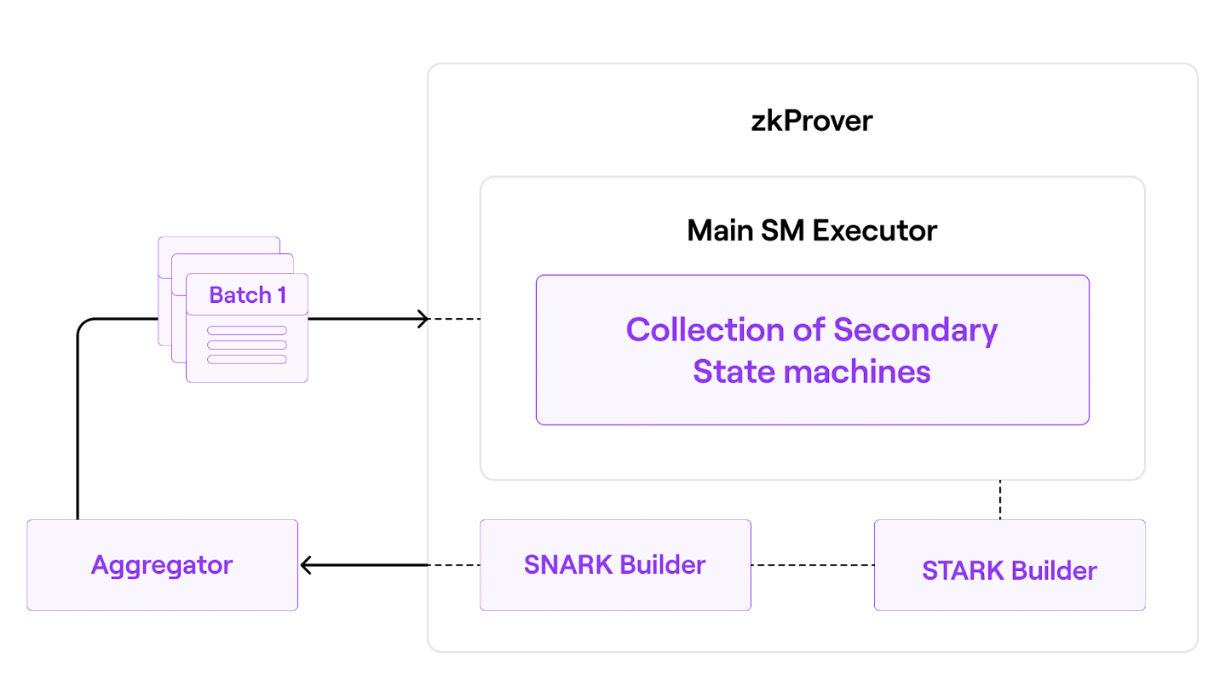
In a nutshell, the zkEVM expresses state changes in a polynomial form. As a result, the constraints that each proposed batch must meet are polynomial constraints or polynomial identities. To put it another way, all valid batches must satisfy specific polynomial constraints. Check out the detailed architecture of zkProver here.
zkEVM bridge¶
The zkEVM bridge is a smart contract that lets users transfer their assets between two layers, LX and LY. The L1-L2 in zkEVM is a decentralized bridge for secure deposits and withdrawal of assets. It is a combination of two smart contracts, one deployed on one chain and the second on the other.
The L1 and L2 contracts in zkEVM are identical except for where each is deployed. Bridge L1 contract is on the Ethereum mainnet in order to manage asset transfers between rollups, while bridge L2 contract is on a specific rollup and it is responsible for asset transfers between mainnet and the rollup (or rollups).
Layer 2 interoperability allows a native mechanism to migrate assets between different L2 networks. This solution is embedded in the bridge smart contract.
Verifier¶
Verifier is a smart contract which is able to verify any zk-SNARK cryptographic proof. This SNARK verifier proves the validity of every transaction in the batch. It is the key entity in any zk-rollup architecture for the prime reason that it verifies the correctness of a proof ensuring a valid state transition.
The verifier contract is currently deployed on the Ethereum mainnet and Goerli testnet.
Transaction life cycle¶
Before getting into a transaction flow in L2, users need some funds to perform any L2 transaction. In order to do so, users need to transfer some ether from L1 to L2 through the zkEVM bridge dApp.
- Bridge
- Deposit ETH.
- Wait until
globalExitRootis posted on L2. -
Perform claim on L2 and receive the funds.
-
L2 transactions
- User initiates tx in a wallet (e.g. MetaMask) and sends it to a sequencer.
- It gets finalized on L2 once sequencer commits to add his transaction.
- Transaction has finalized on L2, but not on L1 (simply put, L2 state is not yet on L1). Also known as a trusted state.
- Sequencer sends the batch data to L1 smart contract, enabling any node to synchronize from L1 in a trustless way (aka virtual state)
- Aggregator will take pending transactions to be verified and build a proof in order to achieve finality on L1
- Once the proof is validated, user’s transactions will attain L1 finality (important for withdrawals). This is called the consolidated state.
The above process is a summarized version of how transactions are processed in zkEVM. We recommend you to take a look at the complete transaction life cycle document.
Design characteristics¶
We plan to create a network which is: permissionless, decentralized, secure, efficient, and comes with verifiable block data.
Development efforts aim at permissionless-ness, that is, allowing anyone with the zkEVM software to participate in the network. For instance, the consensus algorithm will give everyone the opportunity to be a sequencer or an aggregator.
Data availability is most crucial for decentralization, where every user has sufficient data needed to rebuild the full state of a rollup. As discussed above, the team still has to decide on the best configuration for data availability. The aim is to ensure that there is no censorship and that no one party can control the network.
zkEVM was designed with security in mind. And as an L2 solution, most of the security is inherited from Ethereum. Smart contracts will ensure that everyone who executes state changes does so appropriately, creates a proof that attests to the validity of a state change, and makes validity proofs available on-chain for verification.
Efficiency and overall strategy¶
Efficiency is key to network performance. zkEVM applies several implementation strategies to guarantee efficiency. A few of them are listed below:
-
The first strategy is to deploy the consensus contract, which incentivizes the most efficient aggregators to participate in the proof generation process.
-
The second strategy is to carry out all computations off-chain while keeping only the necessary data and zk-proofs on-chain.
-
The way in which the bridge smart contract is implemented, such as settling accounts in a UTXO manner, by only using the exit tree roots.
-
Utilization of specialized cryptographic primitives within the zkProver in order to speed up computations and minimize proof sizes, as seen in:
-
Running a special zero-knowledge assembly language (zkASM) for interpretation of bytecode.
-
Using zero-knowledge tools such as zk-STARKs for proving purposes; these proofs are very fast though they are bigger in size.
-
Instead of publishing the sizeable zk-STARK proofs as validity proofs, a zk-SNARK is used to attest to the correctness of the zk-STARK proofs. These zk-SNARKs are, in turn, published as the validity proofs to state changes. This helps in reducing the gas costs from 5M to 350K.